Method

Generalizable Implicit Motion Modeling module (GIMM). Our GIMM first transforms initial bidirectional flows \(F_{0\rightarrow1},F_{1\rightarrow0}\) as normalized flows \(V_0, V_1\).
Motion Encoder then extracts motion features \(K_0, K_1\) from \(V_0, V_1\) independently.
\(K_0, K_1\) are then forward warped at a given timestep \(t\) using bidirectional flows to obtain the warped features \(K_{t\rightarrow0}, K_{t\rightarrow1}\).
We pass both the warped and initial motion features into Latnet Refiner that outputs motion latent \(L_t\), representing motion information at \(t\).
Conditioned on \(L_t(x,y)\), the coordinate-based network \(g_{\theta}\) predicts the corresponding normalized flow \(V_t\) with 3D coordinates \(\textbf{x}=(x,y,t)\).
For interpolation usage, \(V_t\) is then transferred into bilateral flows \(F_{t\rightarrow0},F_{t\rightarrow1}\) through unnormalization.
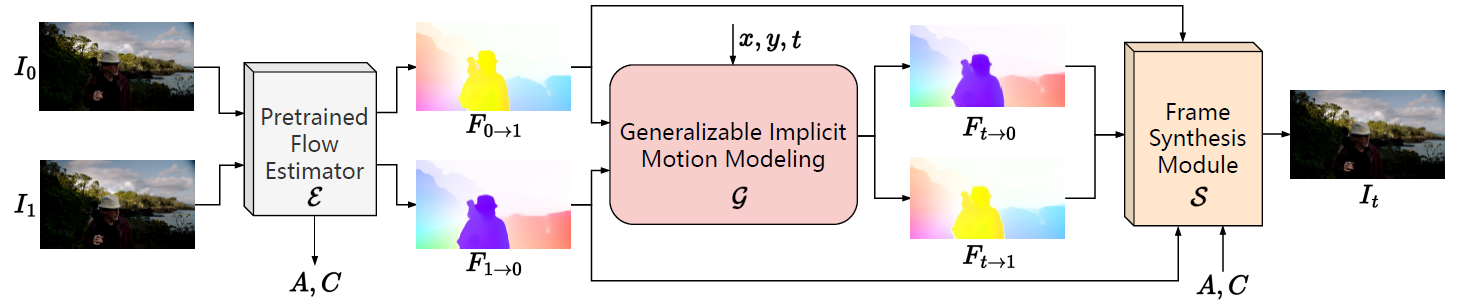
Integrating GIMM with Video Frame Interpolation (GIMM-VFI). GIMM-VFI utilizes a pre-trained flow estimator \(\mathcal{E}\),
to predict bidirectional flows \((F_{0\rightarrow1}, F_{1\rightarrow0})\) and extracts context features \(A\) as well as correlation features \(C\) from the input frames \((I_0, I_1)\).
Given the timestep \(t\), a generalizable implicit motion modeling (GIMM) module \(\mathcal{G}\)
(detailed in Figure \above) takes the bidirectional flows as inputs and predicts bilateral flows \((F_{t\rightarrow0}, F_{t\rightarrow1})\),
which are then passed into a fame synthesis module \(\mathcal{S}\), together with extracted features \((A, C)\), to synthesize the target frame \(I_t\).



